Tutorial 6: Data Mapping
Estimated time: 10 min.
Prerequisites
- PIPEFORCE Enterprise 7.0 or higher
- You have a valid PIPEFORCE Developer account
- You have completed tutorial: Tutorial: Create a new app
- You have completed tutorial: Tutorial: Create and execute a pipeline
- You have a basic understanding of the PEL: Pipeline Expression Language (PEL)
Data Mapping - Intro
As you should already know, a pipeline in PIPEFORCE is an easy to learn low code script, which can do many different things for you. One very important thing is the mapping, conversion and normalization of (JSON) data.
Lets assume this example: You got a customer dataset from the sales system, and you need to make sure, that this data set perfectly fits into the structure of the ERP system. For this, you need some way of converting the source data from the CRM system to target format of the ERP system. To do so, you can use the data mapping power of a pipeline.
Lets assume the customer dataset from the CRM system looks like this:
{
"firstName": "Sam",
"lastName": "Smith",
"age": 34
}
And we want to convert this input dataset into an output format for the ERP system, which expects the customer dataset to have a structure like this:
{
"customer": {
"name": "Sam Smith",
"age": 34,
"isLegalAge": true
}
"mappingDate": "01.01.2022",
"mappedBy": "someUsername"
}
As you can see, we have to do some steps to transform from the source to target format:
- We have to nest every customer data inside the
customerfield. - We have to combine the first and last name into the single
namefield. - The target system expects the additional field
isLegalAge, which doesn’t exist in the source system. The value of this field must be set totruein case age of the customer is > 18, otherwise it must be set tofalse. - Finally, let's assume the target system expects a new field
mappingDate, which contains the date of mapping, andmappedByto contain the username of the user who did the mapping, just for compliance reasons.
Let's see in this tutorial, how to implement this conversion task by using a pipeline script and the Pipeline Expression Language (PEL) .
1 - Create a new data mapping pipeline
Login to the portal https://NAMESPACE.pipeforce.net
Navigate to LOW CODE → Workbench
Select the node of your app or create a new one.
Click the plus icon at the top of the tree.
The new property view opens:
- As property key, use:
global/app/YOUR_APP/pipeline/data-mapping - As mime type, use:
application/yaml; type=pipeline
- As property key, use:
Click SAVE
The new property has been created and the content editor was opened for you.
Now copy and paste this content into the editor, and overwrite any existing data there by this:
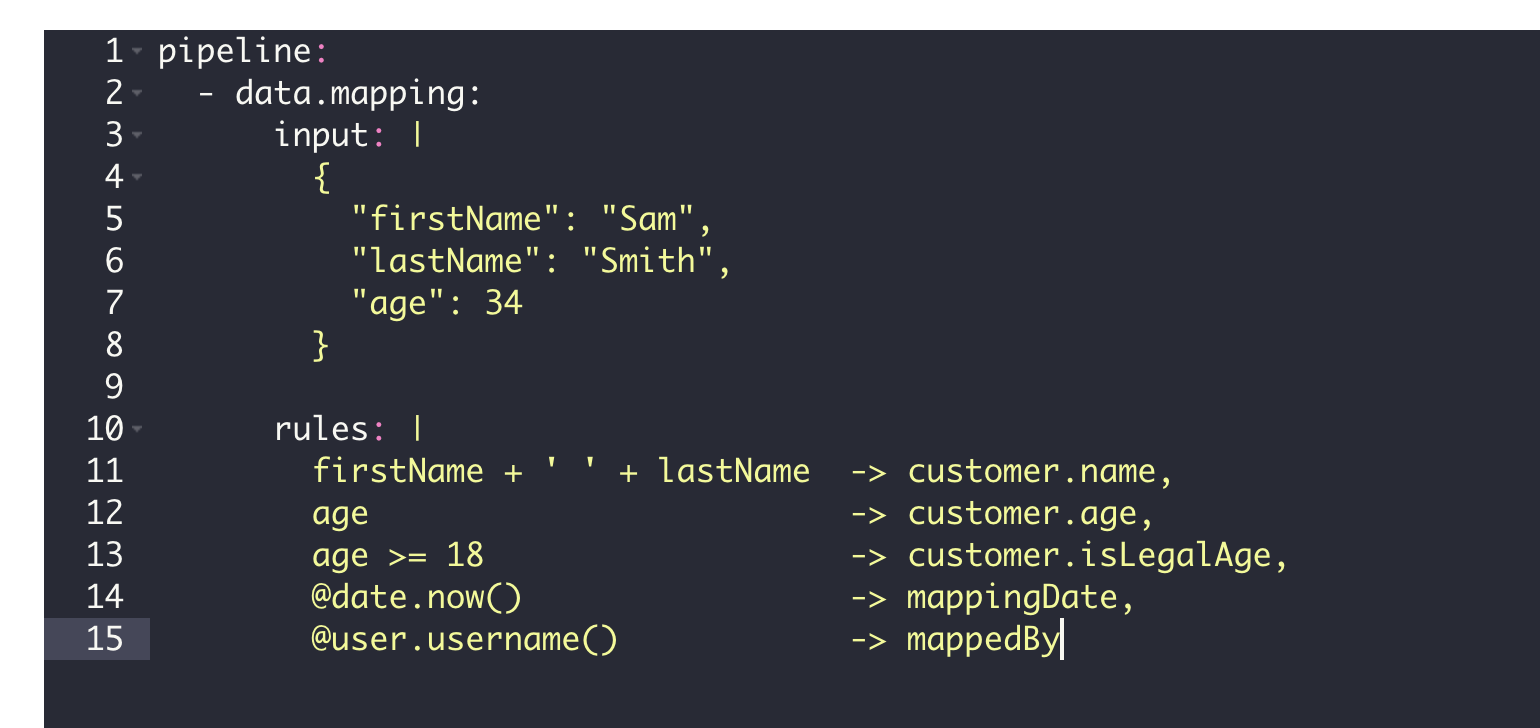
global/app/YOUR_APP/pipeline/data-mappingpipeline:
- data.mapping:
input: |
{
"firstName": "Sam",
"lastName": "Smith",
"age": 34
}
rules: |
firstName + ' ' + lastName -> customer.name,
age -> customer.age,
age >= 18 -> customer.isLegalAge,
@date.now() -> mappingDate,
@user.username() -> mappedByIn this snippet, we created a very simple data mapping configuration:
We used the
data.mappingcommand, which allows to map from one structure to another.The
inputparameter defines the source data as a static JSON string in this example. Besides a static string, this value could also be a pipeline expression (PEL) pointing to some dynamic data in thevarssection or external services. In this example, we want to focus on the data mapping, and keep the rest simple. If the parameterinputis not specified, the current value from the body would be expected as input. Note the handy pipe symbol|here, which is specific to the YAML syntax and allows a multi-line value without additional annotations, ticks or quotes.The
rulesparameter (ormappingRulesin versions < 8.0) defines the mapping rules, which will read from the input data and write to the output data. You can define as many mapping rules as you want. Each mapping rule ends with a comma and a line break at the very end. They will be applied from top to down. The input expression is defined at the left hand side, and selecting + prepares the input data for the mapping. At the right hand side, the output expression is defined. It specifies the location where to write the data in the output structure. Both expressions are separated by an arrow->. Each side can use the pipeline expression language (PEL), and therefore, the full power of this language. It's not necessary to wrap a pipeline expression inside#{and}. So the format on each line should look like this:inputExpression -> outputExpression,As a first rule, we simply concat (= combine) the first and last name separated by a space from input and write the result into the output to the location
customer.name:firstName + ' ' + lastName -> customer.name,The second mapping rule simply copies the age field from the input to the nested
customer.agefield on the output:age -> customer.age,The third rule is an expression, which detects whether the age field on the input contains a value >= 18. Then, it writes the result to the output at the location
customer.isLegalAge:age >= 18 -> customer.isLegalAge,The fourth rule executes the pipeline util
@date, in order to return the current date. Then, it writes this value to the new fieldmappingDateat top level of the output:@date.now() -> mappingDate,The last rule is similar to the previous one and calls the pipeline util
@user, in order to return the username of the currently logged-in user. Then, it writes the result to the new fieldmappedByat the top level of the output:@user.username() -> mappedByNot mentioned here because it is optional: The
outputparameter for the commanddata.mapping. Its value must be a pipeline expression language (PEL), which points to the location (or a sub-path) to write the mapping result to (for example a variable inside thevarsscope). If not specified, it will be written to the body by default. That is the case for our example.
Click SAVE to save the pipeline.
Then click RUN to execute the pipeline which should look like this:
You should then see a result similar to this:
{
"customer": {
"name": "Sam Smith",
"age": 34,
"isLegalAge": true
},
"mappingDate": "16.01.2022 08:54:17",
"mappedBy": "yourUsername"
}This data now can be used and send to an ERP system for example using an additional command.
Congrats, you have created your first data mapping rules in PIPEFORCE!
Report an Issue
In case you're missing something on this page, you found an error or you have an idea for improvement, please click here to create a new issue. Another way to contribute is, to click Edit this page below and directly add your changes in GitHub. Many thanks for your contribution in order to improve PIPEFORCE!